ESP32-ATM0130B3,ST7789とのSPI通信処理1に引き続き、ST7789との通信処理。
今度は、DMA転送を使ったSPI通信。
通信処理本体
基本的な考え方は、上記サンプルにある通り。
秋月のサンプルソースを、単純ESP32対応したものの処理時間が1524msだったのに対して、この対応を行ったソースでは70msと劇的な速度改善が計れた。
ST7789で通信可能でESP32で採りえる周波数のSPI_MASTER_FREQ_40Mを使ったものになる。
SPI_MASTER_FREQ_80Mは、ST7789で情報を受け取ることができず、表示がうまくされなかった。
ちなみにST7789の仕様書を見る限り、理想的な状態での最速は62.5MHz(TSCYCWの最小が16nsなので)になるようだ。
DCピンの対応方法
送信する情報がコマンドなのかデータなのかを判別するピンの操作は、コールバック関数を使い処理することになる。
今回の送信はDMA転送を使う予定なので、ハードウェアでデータの送信が行われる。そのためデータなのかコマンドなのかを送信処理本体で行うと、SPIでのデータ送信とDCピンの状態に齟齬が起きる可能性がある。そのため、コールバック関数内で行うような形になる。
static void transfer_callback(spi_transaction_t *t)
{
if (t->user != nullptr) {
gpio_set_level((gpio_num_t)((uint32_t)t->user & 0xFF), ((uint32_t)t->user & 0xFF00) != 0 ? 1 : 0);
}
}
void initialize()
{
spi_device_interface_config_t devcfg = {
0, 0, 0,
0, // SPI mode
0, 0, 0,
SPI_MASTER_FREQ_40M,
0,
GPIO_NUM_5, //CS pin
0,
transNum_, //We want to be able to queue 7 transactions at a time
transfer_callback,
nullptr
};
ret = spi_bus_add_device(VSPI_HOST, &devcfg, &device_);
}spi_bus_add_deviceでコールバック関数(transfer_callback)を登録、呼び出し側はuserメンバ内に、(void*)(dat_cmd)もしくは(void*)(0x100 | dat_cmd)を代入することで、コールバック側にuserメンバの情報が伝えられDCピンのON/OFFを制御している。
コールバック関数を使う場合、ハードウェアによる転送とは別にCPU処理が呼び出されるため、以下の様に一時的な処理の停滞が発生してしまう。
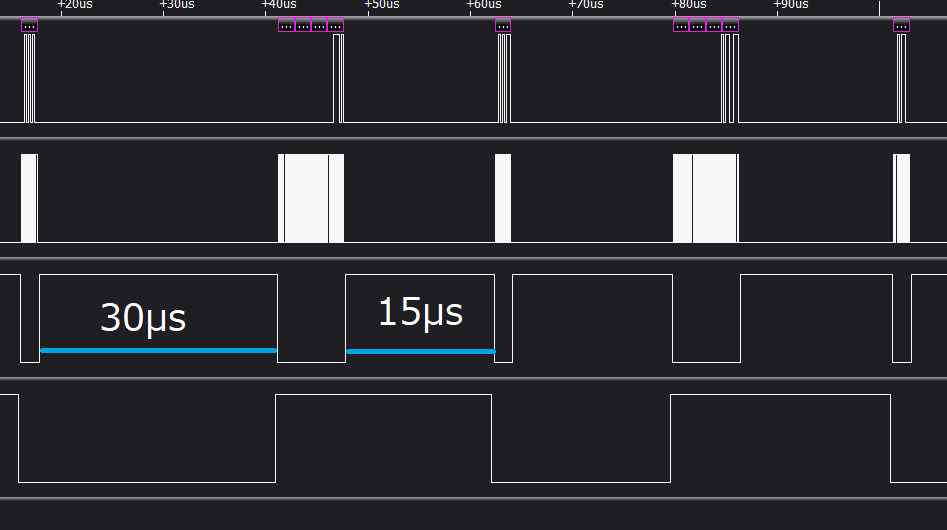
もしかしたら、CPU側での送信用データ作成時間も含まれているかもしれないが。
DMAを使ったデータ転送
こちらも基本的にサンプルソース内のコードと同じ。
void ATM0130::writeData(size_t len, uint8_t *buffer)
{
trans_[1].length = 8 * len;
trans_[1].flags = 0;
trans_[1].tx_buffer = buffer;
auto ret = spi_device_queue_trans(device_, trans_ + 1, portMAX_DELAY);
assert(ret == ESP_OK);
}これが送信用の関数だが、使う呼び出しはspi_device_queue_trans。
またtx_bufferに詰めるのは、通常のバッファ領域ではなくDMA転送用に領域確保したものを使う。
buffer_[0] = (uint16_t*)heap_caps_malloc(bufferNum_ * sizeof(uint16_t), MALLOC_CAP_DMA);heap_caps_mallocでMALLOC_CAP_DMAを指定することでDMA転送用領域を確保したことになる。
これを2つ用意し、spi_device_queue_transで交互にデータを詰め、転送するようにすることでDMA転送を実現できる。
void ATM0130::end()
{
spi_transaction_t* rtrans;
esp_err_t ret;
for (; nQue_ > 0; nQue_--) {
ret = spi_device_get_trans_result(device_, &rtrans, portMAX_DELAY);
assert(ret == ESP_OK);
}
}
void ATM0130::drawRectangle(uint8_t x, uint8_t y, uint8_t width, uint8_t height) {
uint16_t loop = width * height;
start();
setWindow(x, y, width, height);
int index = 0;
for (uint16_t i = 0; i < loop; index++) {
if (index != 0) {
end();
}
uint16_t *buffer = buffer_[index % 2];
uint16_t j = 0;
for (; j < bufferNum_ && i < loop; j++, i++) {
buffer[j] = fig_color;
}
writeData(j * 2, (uint8_t*)buffer);
}
end();
}上のdrawRectangleは指定された領域を塗りつぶす関数なのだが、buffer_[0], buffer_[1]に交互に色情報を詰めて、writeDataでデータを送信するといったことをしている。
end()内では、前回送信したデータの受信処理をしている。
これにより、バッファにデータを詰めるのとSPI通信が並行に動作させることができる。

上のがその送信時の状態。
複数回色データを送信しているのだが、end()内での受信処理以外、SPI送信が連続で行われていることが分かる。end()の処理時間の短縮は難しいが、SPI周波数を上げることで、全体の処理時間の短縮を図ることができる。
- 2021/03/05 修正
上のend()処理と書かれているものの考察が間違っていた。
実際にはコールバック処理が実行されていた模様。
end()処理相当にトリガーを仕込みロジックアナライザで見たところ、SPI転送とは非同期に行われていたことを確認した。 - 2021/03/06 修正
コールバックを行わないプログラムを作成したところend()処理と書かれている部分の時間は短縮されなかった。
この時間、次のSPIトランザクションをハードウェアに転送している時間ではないかと思われる。なので、この時間を取り除くには、送信するデータのサイズを大きくするしかないのではないかと思う。
最後に
ATM0130B3の液晶モジュールは4-line serial interface Ⅰという形式だったのだが、ESP32の場合DCピンを別制御するより、3-line serial interfaceで、純粋にSPI中でデータ・コマンドの識別をさせた方が、ハードウェアSPIを使えるので、実装も単純になるのではないかと考えている。
なぜ、ATM0130B3の4-line serial interfaceを採用したのだろうか。
ここだけちょっと疑問に思ってしまった。
コメント