Flutterの多言語化で、文字列の辞書を作成する基本の方法はAdding your own localized messagesに記述されているarbファイルを作成し、それをgen_l10nで変換するという方法になる。
これをベースとした方法の場合、arbファイルの編集がテキストベースで、またその管理や記述方法から、横並びに俯瞰的に見ることができず管理や翻訳が結構面倒。
GUIベースで文字列を管理できるようなものがないかを調べたところ、エクセルからの変換ができるものがあったので利用してみることにした。
調査したもの
見つけたのは4パッケージ。

- arb_excel
エクセルからarbファイルへの変換を行う。
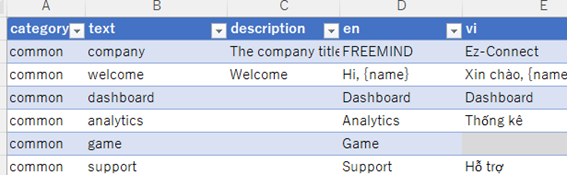
上記の様にテーブル形式でメッセージを管理できるのはいいかもしれない。
ただ別途arbを取り扱うパッケージを用意する必要がある。 - arbxcel
arb_excelからforkし、ちょっとだけ独自進化したパッケージ。 - excel_localization
github側にサンプルがないので具体的なイメージが付かない。
後ソース中にflappy_*.dartというファイルがあった。
後述するflappy_translatorからforkされて作成したものかもしれない。 - flappy_translator
エクセルやCSVファイルから直接言語変換用のクラスを生成する機能を持つ。
ざっと触った感じでは使いやすいのではないかと思う。
以下は、実際に使用したflappy_translatorについて詳細を記述している。
flappy_translator
エクセルやCSVファイルから直接言語変換用のクラスを生成する。
例えば、以下の様なエクセルファイル
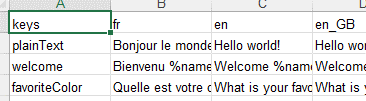
から、以下の様なクラスが生成される。
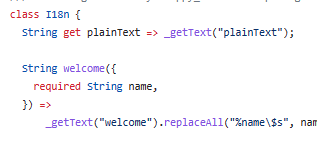
生成されるクラスの感じはgen_l10nから生成されるものと似たような感じ。
エクセルファイルの記載内容
1行目がヘッダーで、A列がキーワード、B列以降が言語。
指定するのは言語名。
パラメータのstart_indexで、どの列(B列、C列など)からを変換対象とするか指定することができるが、無難にデフォルトの1のままが良いだろう。
コメントを generate_comments, comment_languagesのパラメータで指定することができるが、指定可能なのは定義された言語のみなので、上のエクセル例で言うと、frとかenとかの列の内容しかコメント化出来ない。
言語対応の文字列とは異なるコメントを指定したいという要望はかなえることができない。
(arbファイルでは”description”というのを個別に指定することができるけど、flappy_translatorにはそのような機能はない)
変換
flutter pub run flappy_translator
上記コマンドでエクセルからメッセージ用クラスを生成する。
変換のためのパラメータはpubspec.yaml内に記述することになる。
生成ファイル
pubspec.yaml内のパラメータoutput_dir, file_name, class_nameで出力ファイル名やクラス名を制御することができる。
生成されたクラスは、上記の様にエクセル上のキーワードがメソッド名として生成される。
LocalizationsDelegateも自動生成されるのだけど、同一ファイル内に一緒に生成されるので取り扱いが面倒かもしれない。
しかもIntl.defaultLocaleの設定が入っていないので、直接は使用できない感じ。
また変換された言語単位の文字列をstaticなmapに保存されているところは好みが分かれるところ。
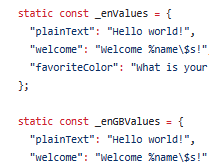
パラメータdepend_on_contextがtrueの場合はオブジェクトとして利用する。
この場合「class. of(context).変数名」という利用方法になる。
falseの場合はstatic変数になり、ある意味グローバルでアクセス可能になる。
実際の利用方法
- メッセージファイルの置き場所
- 変換後のクラスファイルの置き場所
- 変換パラメータ
- 変換タスクの定義
- 実装からの呼び出し方法
メッセージファイルの置き場所
サンプルではプロジェクトルートに配置している。
変更頻度が高いのであれば、ファイル名とかにも気を付け、わかりやすい場所になるように調整するのが良いのかもしれない。
例作ったサンプルでは、string.xlsxとすることで、エクスプローラーの最後に表示されたので、ファイルの指定がしやすくなった。
また、ファイルの起動に関しては、VSCodeのエクスプローラーから直接エクセルが起動できるようにOpenなどの機能拡張を利用するのが良いかもしれない。

変換後のクラスファイルの置き場所
プロジェクトから参照しやすいように、lib/l10nに生成するようにした。
またクラス名はflappy_translatorのサンプルと同様にI18nとする。
またlib/l10nフォルダは.gitignore等でgit管理対象外にするのが良い。
クラス名にI18nを使用するのは、単純に実装時の記述が短くなるから。
変換パラメータ
pubspec.yaml内に記述する内容としては、結果として以下の様にしている。
flappy_translator:
input_file_path: "string.xlsx"
output_dir: "lib/l10n"
file_name: "i18n"
class_name: "I18n"
delimiter: ","
start_index: 1
depend_on_context: true
use_single_quotes: false
replace_no_break_spaces: false
expose_get_string: false
expose_loca_strings: false
expose_locale_maps: false
generate_comments: true
comment_languages: ["en"]コメントの生成は”en”ベースにしている。
変換タスクの定義
メッセージの変換はそれなりの頻度で行うと思われるので、変換処理をタスクに入れておくと便利かもしれない。
そしてメッセージファイル保存をトリガーにそのタスクを実行する(例えばTrigger Task on Saveを使用するなど)と手間がない。
タスクは以下の様な感じになる。
{
// See https://go.microsoft.com/fwlink/?LinkId=733558
// for the documentation about the tasks.json format
"version": "2.0.0",
"tasks": [
{
"label": "build message resource",
"type": "flutter",
"command": "flutter",
"args": [
"pub",
"run",
"flappy_translator",
],
},
]
}実装からの呼び出し方法
LocalizationsDelegateの派生(もしくはimplements)したものを作る。
LocalizationsDelegateのメソッドのオーバーライド部分と、MaterialAppからの呼び出しに関する部分は以下の様になる。
late I18n _message;
I18n get m => _message;
@override
bool isSupported(Locale locale) => supportedLocals.contains(locale);
@override
Future load(Locale locale) {
Intl.defaultLocale = locale.toString();
final ret = I18n.load(locale);
ret.then((value) => _message = value);
return ret;
}
@override
bool shouldReload(covariant LocalizationsDelegate old) => false;
@override
Type get type => I18n;
static final Set<Locale> supportedLocals = I18nDelegate.supportedLocals;
Iterable<LocalizationsDelegate<dynamic>> get localizationsDelegates => [
this,
GlobalMaterialLocalizations.delegate,
GlobalCupertinoLocalizations.delegate,
];MaterialAppでlocalizationsDelegatesとsupportedLocalesの呼び出しは、上のisSupportedとlocalizationsDelegatesを呼び出すようにする。
実際に使用する箇所は、「I18n.of(context).XXXX」もしくは上のクラスの「m.XXXX」を呼び出す形。
ちなみに私はGetXで上記定義をアプリケーション用のVMとしているので、それをDIで呼び出すことで使用可能にしている。
そちらの方が実装量が少なくなるので。
実際の実装は、「vm.m.XXXX」となる。
問題点
使ううえで2点ほど問題が出た。
どちらも下位依存のexcelパッケージの問題?なのかな。
- フリガナ情報が正しく処理されない。
例えば「漢字」とセルに入力すると、その日本語メッセージは「漢字カンジ」になってしまう。
使用しているexcelパッケージでフリガナ(Phonetic)情報を正しく処理していなかったから。
これについては修正を入れて、パッケージ側にPull requiest出したので、取り込まれるのではないかと思う。 - 文字の処理の順序がおかしくなり、正しく処理されない。
エクセルの不具合なのかexcelパッケージの認識漏れなのか不明。
原因は、エクセルのセル文字列を保存しているSharedStringsの処理に起因する問題。
SharedStringsには文字情報をユニークな状態で管理しているのだけど、データによってはユニークであるべき文字情報がそうでない状態になっている。
excelパッケージ側はユニークであるという前提で処理しているため、正しく処理できていなかった。
自分持ちのexcelパッケージでは対処済みなのだけど、これでいいのかどうかが不明なので、まだPull requiestを出していない。
一応エクセル上で、全体をコピーしその後ペーストすることで正しい状態にはなる。
コメント